






Responsable: Alberto J. Ferrer
Colaboración: Daniel Aguado (Grupo de Investigación CALAGUA, Dpto. de Ingeniería Hidráulica y Medio Ambiente), Jesús Picó y José Camacho (Dpto. de Ingeniería de Sistemas y Automática).
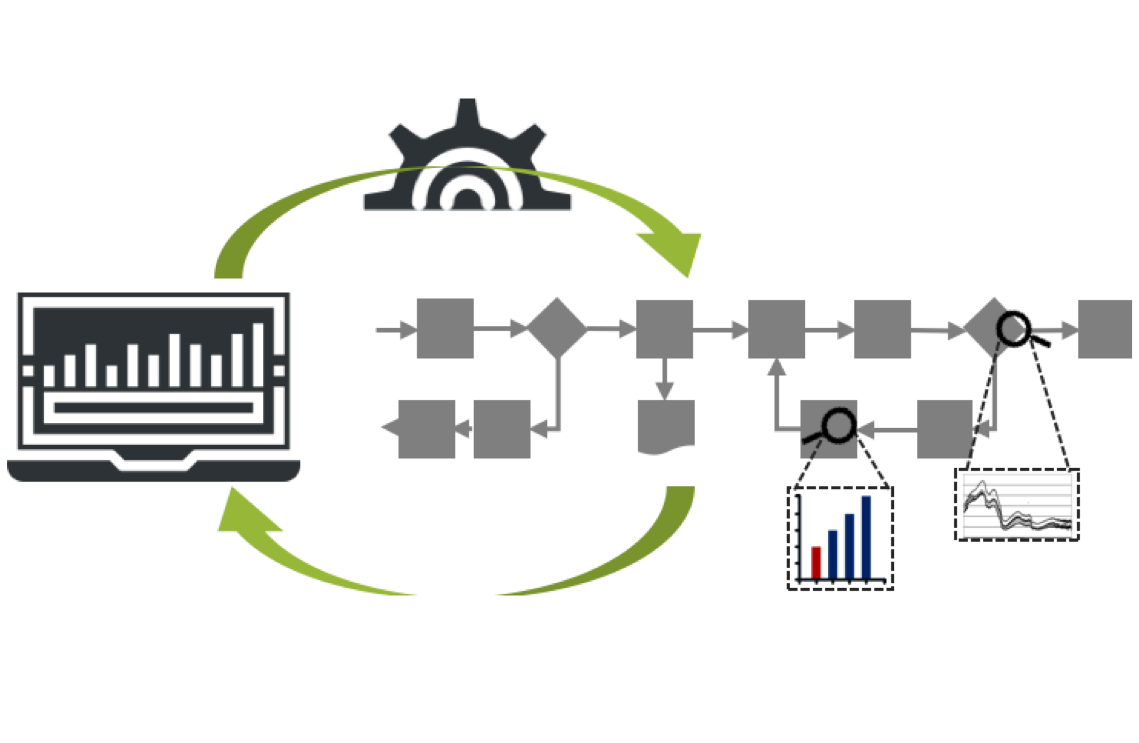
En los modernos procesos industriales se generan enormes cantidades de datos. En esta línea se exploran las potencialidades de las técnicas estadísticas multivariantes de proyección sobre estructuras latentes (Análisis de componentes principales – PCA, mínimos cuadrados parciales – PLS, ...) para extraer la información de estos datos y utilizarla en el análisis, identificación de fallos y puntos críticos del proceso, así como para ayudar en el diagnóstico de las variables responsables y desarrollar modelos empíricos de monitorización de procesos en tiempo real (control estadístico de procesos multivariante - MSPC).
Se estudia también la adaptación de los métodos de control estadístico multivariante de procesos (MSPC) a las particularidades de los procesos industriales por lotes, quienes, a pesar del enorme valor añadido que suelen tener, y debido a su complejidad, en la práctica funcionan sin ninguna forma efectiva de monitorización en tiempo real. Se investiga la forma de desarrollar e implantar sobre procesos por lotes complejos reales un sistema integrado que permita la rápida detección y el diagnóstico de fallos, la monitorización en tiempo real y el establecimiento de modelos predictivos (soft-sensors) mediante las novedosas técnicas multivariantes de análisis de matrices de datos tridimensionales (3-way data).
El desarrollo de técnicas de análisis instrumental (espectrometría, cromatografía ...) y de la tecnología de sensores hace posible generar una gran cantidad de datos asociados a cada muestra recolectada. La compleja estructura de los datos registrados requiere una serie de técnicas específicas para obtener buenos modelos de calibración multivariable. El análisis de estas estructuras complejas conduce a la aplicación de un modelo de proyección multivariable, cuyo objetivo básico es adaptarse a la mejor estructura posible de acuerdo con criterios de interpretación o predicción preestablecidos.
Los principales modelos tradicionalmente empleados han sido PCA y PLS, con sus extensiones desplegadas, para el despliegue de estructuras cúbicas o n-dimensionales. La mejora en la capacidad de cálculo computacional en las últimas décadas ha permitido la incorporación eficiente de algunos modelos más generales, como el Tucker3, PARAFAC y N-PLS, los cuales permiten estudiar la estructura de datos directamente sin necesidad de que sea desplegada.
Responsable: Alberto J. Ferrer
Colaboración: Daniel Aguado (Grupo de Investigación CALAGUA, Dpto. de Ingeniería Hidráulica y Medio Ambiente), Jesús Picó y José Camacho (Dpto. de Ingeniería de Sistemas y Automática).
Responsable: Alberto José Ferrer Riquelme
Colaboración:: José Camacho, Jesús Picó y Javier Sanchís (Dpto. de Ingeniería de Sistemas y Automática).
En esta línea de investigación se aborda el estudio de diversos procedimientos que permitan desarrollar la estrategia MESPC: integración del MEPC (Multivariate Engineering Process Control) con el MSPC (Multivariate Statistical Process Control). Para ello se aborda el estudio de modelos de series temporales autorregresivos y de medias móviles vectoriales para el análisis conjunto de parámetros de calidad, de productividad y de proceso en sistemas productivos con dinámica. Como caso particular de estos modelos, se considera la aplicación de funciones de transferencia multi-input/multi-output en el modelado de relaciones dinámicas unidireccionales.
El control ingenieril de procesos multivariante se aborda mediante el Control Predictivo Basado en Modelos (CPBM), metodología que hace uso de los modelos indicados previamente para desarrollar ecuaciones predictivas y algoritmos de control, cuyo funcionamiento se plantea como uno de los objetivos de investigación. La monitorización estadística de procesos se aborda investigando las variables a monitorizar, así como los gráficos de control a implementar. Por último esta línea de investigación implica el estudio de las ventajas de la integración MESPC ante causas especiales de variación, comparando su eficacia con la del sistema MEPC (sin monitorización).
Analysis of medical images is one of the most relevant topic within Image Analysis. Typically, this tasks have been performed by extracting features (typically textural) from each of the different types of these images (X-rays, CT scan (computed tomography scan), MRI (magnetic resonance imaging), ultrasound, nuclear medicine imaging, including positron-emission tomography (PET)), afterwards using these features for enhancing some particular phenomenon when looking inside the image, or for predicting or classifying when using the whole information in the image.
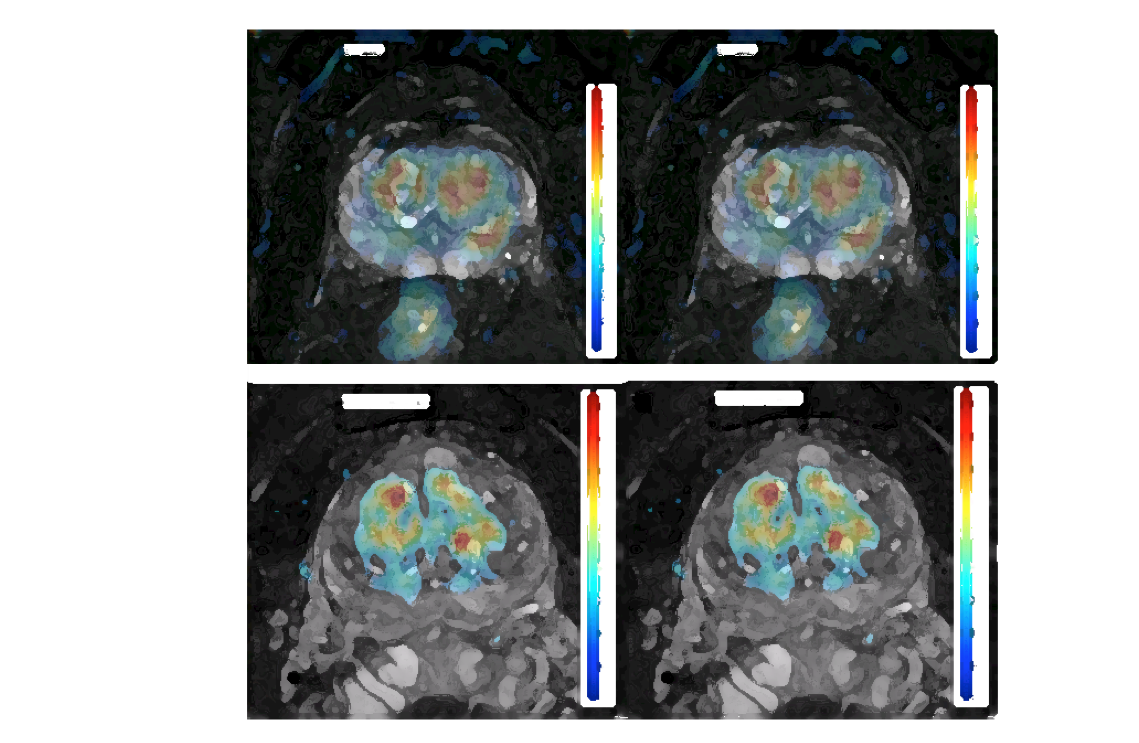
Furthemore, in MRI a different approach can be applied, which consists on using the whole sequence for compressing it into new and clinically informative images: the imaging biomarkers. The new images, by using the physico-chemical knowledge related to the presence and development of certain biological processes (e.g. cancer tumors), provide, for each pixel in the images, quantitative and objective information that can be interpreted by doctors, improving the diagnosis and giving insight about how tumors develop.
However, these imaging biomarkers suffer different drawbacks: they are calculated pixel by pixel, increasing the uncertainty and reliability in the estimation, some of the parameters obtained have a difficult physiological interpretation, there are several models that can be applied… and despite the high number of biomarkers available, only a few are used in practice by radiologists for diagnosis.
In order to overcome this situation, this line is focused on the development of new imaging biomarkers that fulfill the following conditions:
• They take advantage of the whole correlation structure in the MR sequences, thus providing robust imaging biomarkers.
• They inform about their reliability. In common imaging biomarkers calculation, only the value is provided, no matter its reliability and/or uncertainty.
• They are easy-to-interpret biomarkers: they are directly related to specific curves linked to the biological phenomena of interest.
This is done by using multivariate statistical models based on latent variables, which extract out the information gathered in the sequences directly from the patient data, by using clinical prior knowledge. Models such as Multivariate Curve Resolution are used for these purposes.
Nevertheless, providing a full set of imaging biomarkers to radiologists do not solve the problem of which biomarker or set of biomarkers select for diagnosis and/or prognosis. Using Partial Least Squares, it is possible to compress all relevant imaging biomarkers into just one final image, the Virtual Biopsy, which provides doctors with an ultimate predictive and probabilistic map that informs about the presence and/or aggressiveness of a tumor; as well as its corresponding reliability at each pixel location.
Responsable: José Manuel
Responsable: José Manuel Prats
From late 70’s, image analysis has been used in industry, initially for defect detection and pattern recognition tasks, mainly objects segmentation and classification. Technology evolution allowed introducing RGB cameras, so these tasks were broaden to e.g. color grading.
The introduction of multivariate statistics in image analysis, known as Multivariate Image Analysis (MIA), let to perform not only the aforementioned activities, but also more complex ones, such as process monitoring, by controlling the process evolution with computer vision systems. MIA has been used in the mineral industry for monitoring froth flotation processes, in the snack industry for monitoring and controlling the snack flavor and aroma, in the tile industry for color grading, in the metallurgic for final product appearance, etc.
Nowadays not even these, but also NIR hyperespectral cameras are available. They are being introduced in the pharmaceutical and food industry for e.g. assessing the concentration and spatial homogeneity of the different chemical compounds of tablets, or for predicting different quality parameters of diseases in fruits. These tasks can only be performed by using multivariate statistical models based on latent variables, since they are the only ones able to segregate the whole spectrum into those related to the pure chemical compounds in a mixture, hence allowing experts to validate the final result. This result can be extended, not only to NIR hyperspectral cameras, but also to other complex ones such as those based in EDX (energy dispersive X-ray).
All these monitoring, detection-focused and prediction systems are developed and related to big-data environments where Industry 4.0 is evolving, which need for robust data science methods such as those provided by MIA. This line therefore constitutes the way for allowing these rich databases to provide useful information to the Industry, improving their knowledge about the processes and the quality of the final products.
En los últimos tiempos, las ciencias “ómicas” (genómica, transcriptómica, metabolómica, etc.) han experimentado un gran avance gracias a las nuevas tecnologías de alto rendimiento que permiten el estudio simultáneo de miles de genes, tránscritos, metabolitos, etc. Así pues, la bioinformática ha cobrado un especial interés, ya que utiliza herramientas informáticas y estadísticas para extraer información biológica de los miles de datos generados, con el objeto de encontrar la causa de una enfermedad, descubrir nuevos fármacos o incluso, en un futuro, diseñar tratamientos médicos personalizados. En concreto, nuestro grupo tiene abiertas líneas de investigación en transcriptómica y metabolómica.
En transcriptómica se estudia la expresión génica, es decir, la actividad biológica de los genes. Cuando un gen se expresa, se generan varias “copias” del mismo (tránscritos) que darán lugar a la formación de proteínas. Así, cuando un gen se expresa en individuos enfermos pero no en individuos sanos, será un gen cuya función estará relacionada con la enfermedad en cuestión. Tanto los microarrays (micromatrices de ADN) como las nuevas técnicas de secuenciación masiva (Next Generation Sequencing Technologies) permiten estimar simultáneamente la expresión de miles de genes o incluso de todo el genoma, dando lugar a estructuras de datos multivariantes (ya que se estudiarían miles de variables, en este caso, los genes). Por tanto, es indispensable el uso eficiente de los métodos estadísticos para diseñar y analizar este tipo de experimentos con el fin de extraer de los mismos información biológica relevante.
La metabolómica viene a completar las áreas de conocimiento previamente abarcadas por la genómica y la proteómica, mediante la medida cuantitativa de los metabolitos endógenos presentes en muestras biológicas de distinto origen (orina, plasma, células, tejidos). Los metabolitos son los productos finales de las funciones de genes y proteínas, por lo que su medida es un buen reflejo del estado fisiológico y fenotípico en el que se encuentra el organismo en el que se hallan. El metaboloma desde un punto de vista analítico se considera como un conjunto de compuestos químicos (metabolitos) presentes en un sistema biológico (célula, tejido u organismo), con comportamiento dinámico y que presentan una gran variabilidad estructural. En la actualidad existen distintas plataformas analíticas para llevar a cabo su medida, entre ellas en los últimos años han destacado dos plataformas: i) resonancia magnética nuclear (RMN) y ii) espectrometría de masas (MS) acoplada a cromatografía líquida (LC) o de gases (GC). El análisis del metaboloma de una muestra genera una compleja estructura de datos que requiere de métodos estadísticos multivariantes para su manejo e interpretación.
Responsable: Sonia Tarazona
Diferentes estudios sugieren que el número de dimensiones en la percepción olfativa es de unas 20-30. Dado el elevado número de dimensiones, describir la sensación que produce un determinado olor no resulta sencillo. Por esta razón, es complicado llegar a un consenso a la hora de clasificar olores, o bien desarrollar mapas sensoriales que pongan de manifiesto las similitudes y diferencias entre los descriptores utilizados a la hora de describir un determinado olor. Distintas bases de datos contienen información sobre el perfil olfativo de sustancias químicas o bien de perfumes comerciales. Esta línea de investigación pretende fundamentalmente analizar con técnicas estadísticas multivariantes las distintas bases de datos olfativas disponibles en la bibliografía con distintos objetivos: clasificar descriptores olfativos, clasificar perfumes, investigar el número de dimensiones del espacio olfativo, interpretar las dimensiones psicológicas relevantes de este espacio perceptual, desarrollar mapas sensoriales de olores en general y de perfumes en particular, avanzar en la comprensión de los mecanismos involucrados en la percepción olfativa, etc.
Responsable: Manuel Zarzo
Responsable: Manuel Zarzo
Colaboración: Fernando J. García-Diego
Las obras de arte deben mantenerse en ambientes controlados que aseguren unas condiciones óptimas de conservación a largo plazo. Esto es relativamente sencillo en museos que disponen de sistemas de climatización, pero muchas veces es difícil controlas las condiciones ambientales que afectan al patrimonio cultural. Para monitorizar el mocriclima que está en contacto con las obras de arte pueden emplearse sensores de temperatura y humedad relativa, que registran los datos a lo largo del tiempo. Si se colocan múltiples sensores en un espacio amplio, como una iglesia por ejemplo, durante un largo periodo de tiempo, al final se dispone de una base de datos que requiere ser analizada con técnicas estadísticas multivariantes. El análisis de estos datos permite caracterizar las diferencias registradas entre los distintos sensores. A partir de los resultados se puede valorar de modo preliminar si las condiciones de conservación resultan apropiadas. También se pueden proporcionar algunas recomendaciones para mejorar dichas condiciones.